Learnings from Migrating Legacy to Microservices
Distilling the last 2 years into one post.
Distilling the last 2 years into one post
In September 2017, I was one year into my job at TransferWise, working on our offering to businesses. I had learnt so much on how to build a new product, ship it to customers and iterate with the gathered learnings. And yet, despite all the product knowledge we’d gathered as a team, we were still facing a harsh reality. Our platform was built for consumers, with no hard requirements on availability or performance. When it came to powering payment rails for large businesses, it crumbled.
We knew that this kind of scale was difficult to achieve through our inflexible monolith. We had been working on a few microservices for other use cases, but the effort to use them for our backbone was at its infancy. It was a perfect match: Massive impact for our mission of making money without borders, and a novel personal learning opportunity. So, I switched to working on one of our core microservices, moving legacy code and user flows over.
It’s been almost 2 years on this journey, and I’d love to share two of my top learnings on how best to migrate away from legacy. They’ve been my “north star” principles in deciding on what to do and how to do it. I’ve tried to make them as tech-agnostic as possible, so that you can utilise them in your own legacy migration projects.
1. Anchor on the customer problem.
If I had to choose one, root principle to follow, this would be it.
At first glance, it feels odd to mention within the context of a system-wide refactor. After all, didn’t the whole problem of legacy come about because we were so focused on customer problems we had no time to refactor anything?
How can I implement an architectural vision when I have to justify it has customer value?
In the last 2 years, I’ve found that these sentiments are caused by a false dichotomy that should be torn apart at every chance:
Investing in tech and investing in product are mutually exclusive.
As an engineer, your contributions towards investing in tech or product need not be a zero-sum game, where when you work on one, you damage the other. Just the opposite, your goal should be to create customer value by investing in your own tech, and prioritising those investments in line with how big a customer problem they’re solving.
Let’s take an example that hits home for me - remodelling part of our payments architecture. 2 years ago, I joined this process with a specific goal: Increasing the availability, performance and throughput of our payments creation flow. Our legacy had tons of bottlenecks and inconsistencies, causing angry customers and plenty missed opportunities on scaling the product. The amount of work needed to get to where we wanted seemed overwhelming (and we’re still not there, it’s always Day 1).
Looking back over those 2 years, the clarity of that goal was a blessing we kept coming back to as ground truth. Every planning, we wrote down what we did that we planned, what we did that we hadn’t planned for, and what was left. Then we went though all those items, understanding how exactly we solved a problem by doing the things we did, how the problem space changed that forced us to do unplanned work, and what problems we were hoping to solve next. This guided us through prioritising and executing as a team of 3 engineers. Whenever we felt lost due to changing circumstances, we found that going back to the original “What is the problem we’re solving?” question helped us correct our bearings.
I admit, it’s not trivial to find a meaningful link from a legacy migration, or a new tech project, to customer value. You may be thinking of your own team, and struggling to visualise how your work will create value. If this is the case, there are a few likely scenarios:
- Your project is a bit too removed from the end user, so it’s hard to find the right metrics to look at. If this is the case, you need to ask yourself who your “customer” is, and identify better metrics for tracking them. For example, if you’re in a team that owns service provisioning, it’s definitely difficult to tie that to the end user. Still, one derived metric could be how fast engineers can get a new service up and running. You should be tracking these metrics and getting feedback from other engineers just like a product manager would do for end-users.
- You’re not working on the right thing. Stop. Don’t create that CRUD service because you think this makes the codebase more modular. Understand why you’re building what you’re building.
2. Strangle user flows, refactor, repeat.
This one is the technical equivalent of the first learning, and I urge you to follow it whenever possible. Strangler pattern is well-documented, but in a nutshell, it’s the process of gradually extracting small bits of functionality into the new codebase until no legacy remains.
Here’s how our migration path looks like (middle being the current state):
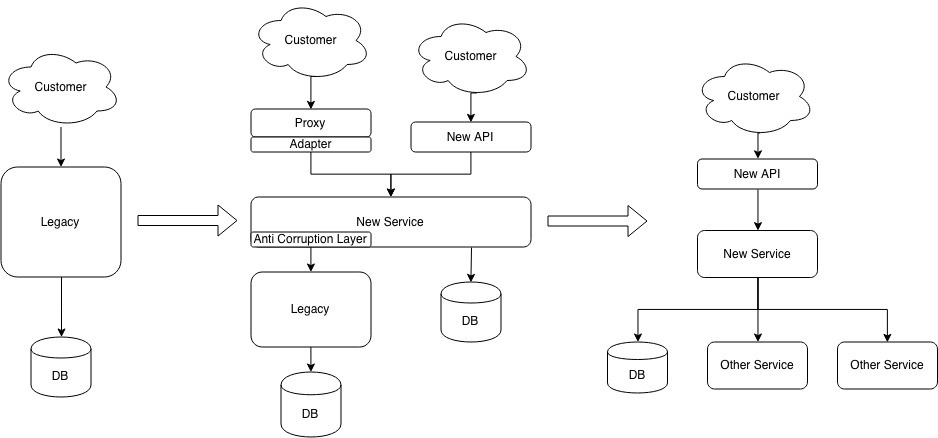
The eagle-eyed reader will notice that this is not exactly the textbook Strangler pattern as described by Martin Fowler.
The middle part does not look like your new service is migrating functionality that is “on the edges”. It’s pretty much at the center of the whole migration process. Why is that?
The answer lies in the words “user flow”. In our user flow, one user action would trigger a lot of business logic, orchestrate different functions, and return an aggregated collection. The problem was, most of these orchestrated bits were now unowned, being part of a legacy codebase in a fast-changing team. Knowledge was already lost due to poor documentation. As a result, we found it difficult to find what the “edges” were to extract and how they would all end up fitting together.
We needed a way in which we could control and learn about the evolution of the domain we were extracting.
After trying to take out bits and pieces of the business logic first, without doing much proxying of customer flows, we found we were getting no meaningful learnings. Also, we were still clueless on how we would end up fitting this into the whole. So we changed course, and set ourselves to first own the customer flows:
- We would proxy the old APIs to our service, even if it meant at first we’d be a simple pass through to legacy;
- We would expose a new, simpler API, which we expected new clients to use and older clients to migrate to.
This enabled us to:
- strangle functionality that is part of the user flow, starting with the business logic and moving to the orchestration later, transparently to users while maintaining the ability to check for correctness of new code;
- define contracts for what the orchestration APIs should look like, and what kind of different subdomains exist within our bounded context (you’ll be familiar with these terms if you’ve read about Domain Driven Design);
- understand and classify critical and non-critical dependencies of our service, allowing us to set appropriate SLAs;
- help the understanding of legacy domains across engineering and bring attention to potential problematic domains that should be fixed/extracted;
- control the evolution of our domain and user flows, given changing requirements.
Now, with a better understanding of our domains and a better vision for what we can strive towards, we can repeat this process when we see value out of it.
The above is only one example of how you can use your user flows to learn about your legacy domain while shipping solutions to customer problems. It will look vastly different given your own circumstances, whether you’re a business-logic heavy or a data-heavy domain, whether you have synchronous or asynchronous processing requirements etc. The technicalities is not a one size fits all, but the concept is:
Strangling your user flows will allow you to solve your customer problems, and learn more about your legacy, at the same time.
Bonus tip: Teach your newbies how legacy works! I completely disagreed with this until a few months ago, when I had the pleasure of onboarding a new engineer to our service. Even if you believe it’s not a great bit of code and people are better off not interacting with it, in the worst case you expand the knowledge of legacy, removing yourself as a single point of failure. In the best case, your newbies challenge your assumptions in ways that expand your understanding.
Those are my top learnings from a rollercoaster 2 years. It’s still Day 1, and I’m sure I’ll get to eat my words here, but if you’d like to share your own experiences and learnings, have any questions or feedback, feel free to contact me over at isemailfine@gmail.com. Email is, indeed, fine.